We are happy to inform that our code has been released! Please click the
Codebutton to play with TAPEX.
In this project, we present TAPEX (for Table Pre-training via Execution), a conceptually simple and empirically powerful pre-training approach to empower existing models with table reasoning skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
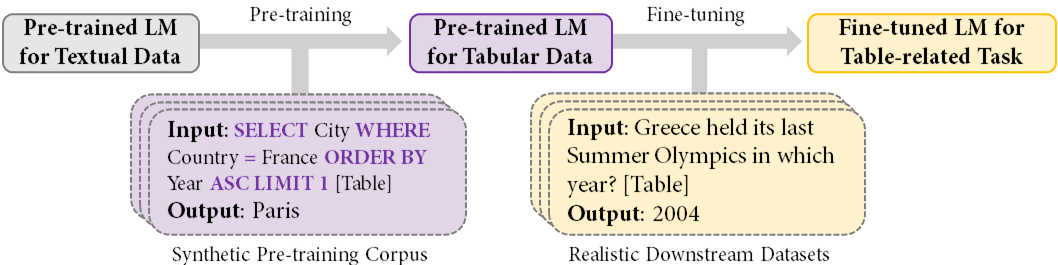
The central point of TAPEX is to train a model to mimic the SQL query execution process over a table. We believe that if a model can be trained to faithfully execute SQL queries, then it must have a deep understanding of table structures and possess an inductive bias towards table structures.

Meanwhile, since the diversity of SQL queries can be guaranteed systemically, and thus a diverse and high-quality pre-training corpus can be automatically synthesized for TAPEX.
🏆 TAPEX = SOTA on Four Benchmarks
We evaluate TAPEX on two tasks 💬 Table Question Answering and 🔎 Table Fact Verficiation.

Experimental results demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin, and our model achieves new state-of-the-art results on four well-known datasets, including:
- improving the WikiSQL denotation accuracy to 89.5 (📈+2.3).
- improving the WikiTableQuestions denotation accuracy to 57.5 (📈+4.8).
- improving the SQA denotation accuracy to 74.5 (📈+3.5).
- improving the TabFact accuracy to 84.2 (📈+3.2).

More importantly, our backbone is a simple Transformer-based Encoder-Decoder model without any task-specific architecture, which can be extended to any kind of downstream task.
⚔️ TAPEX v.s. Previous Table Pre-training
Our TAPEX can achieve significantly better results compared to previous table pre-training techniques, with a much smaller synthesized pre-training corpus.
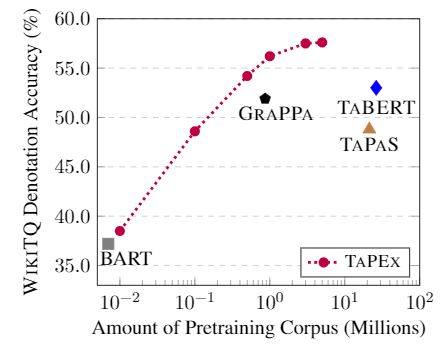
| Pre-training Model | Pre-training Task | Pre-training Scale | WikiTQ Acc |
|---|---|---|---|
| TAPAS (Herzig et al., 2020) | Masked Language Model | 21.3 Million | 48.8 |
| TaBERT (Yin et al., 2020) | Masked Column Prediction + Cell Value Recovery |
26.3 Million | 53.0 |
| GraPPa (Yu et al., 2020) | Masked Language Model + SQL Semantic Prediction |
0.9 Million | 51.9 |
| TAPEX (Ours, 1 Million) | SQL Execution | 1.0 Million | 56.1 |
| TAPEX (Ours, 5 Million) | SQL Execution | 5.0 Million | 57.0 |
WikiTQ refers to the challenging WikiTableQuestions dataset (Pasupat and Liang, 2015).
😉 Other Interesting Work
- https://github.com/microsoft/IRNet
- https://github.com/microsoft/ContextualSP
- https://github.com/JasperGuo/Unimer
📍 Citation
If you find our work useful to you, please kindly cite it by:
@misc{liu2021tapex,
title={TAPEX: Table Pre-training via Learning a Neural SQL Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Morteza Ziyadi and Zeqi Lin and Weizhu Chen and Jian-guang Lou},
year={2021},
eprint={2107.07653},
archivePrefix={arXiv},
primaryClass={cs.CL}
}